Franske ITC-2480 Lab 4: Difference between revisions
Riptide wave (talk | contribs) |
BenFranske (talk | contribs) (Update to mjnk version) |
||
| (21 intermediate revisions by the same user not shown) | |||
| Line 2: | Line 2: | ||
Linux is a very text file-oriented operating system. As we've learned most of the settings for the operating system are held in text files in the /etc directory and most of the commands that are used to manipulate the system take text input or give text output. Beause of this it's very important to be able to edit and manipulate text on the system which will be a key focus of this lab. In addition, we'll practice creating compressed files, which is useful for backing up files, and creating links between locations on the system. | Linux is a very text file-oriented operating system. As we've learned most of the settings for the operating system are held in text files in the /etc directory and most of the commands that are used to manipulate the system take text input or give text output. Beause of this it's very important to be able to edit and manipulate text on the system which will be a key focus of this lab. In addition, we'll practice creating compressed files, which is useful for backing up files, and creating links between locations on the system. | ||
In this lab you will perform the following tasks: | |||
* Edit text files using nano and vi | |||
* Learn how to manipulate command output | |||
* Search for files | |||
* Archive and Compress files using tar | |||
* Create links between directories | |||
You will be introduced to the following commands: | |||
*'''[https://linux.die.net/man/1/vi vi]''' | |||
*'''[https://linux.die.net/man/1/nano nano]''' | |||
*'''[https://linux.die.net/man/1/less less]''' | |||
*'''[https://linux.die.net/man/1/find find]''' | |||
*'''[https://linux.die.net/man/1/locate locate]''' | |||
*'''[https://linux.die.net/man/8/updatedb updatedb]''' | |||
*'''[https://linux.die.net/man/1/ln ln]''' | |||
=Lab Procedure= | =Lab Procedure= | ||
==Prerequisites== | ==Prerequisites== | ||
Open an SSH console to your Linux system using the PuTTY software, login with your standard user account | |||
==Text File Editing== | ==Text File Editing== | ||
'''''[https://www.youtube.com/watch?v=LnVsTA8_mQo Video Tutorial - Text File Editing]''''' | |||
<ol> | |||
<li> Change to the ''/var/www/html'' directory which is where the Apache webserver stores it's site files by default.</li> | |||
<ul> Verify you can see an ''index.html'' file inside of this directory by listing the contents of the directory. Note who the ''owner'' and ''group owner'' of the file are.</ul> | |||
<li> Open up a web browser on your host computer and verify that you can browse to the IP address of your Linux system and still see the "It works" page that you saw in [[Franske ITC-2480 Lab 2#Install the Apache 2 Webserver|lab 2]] after installing Apache.</li> | |||
<ul> Before we start making any changes it's a good idea to save an unmodified copy of the file you'll be working on so make a copy of the ''index.html'' file and name the copy ''index.html.orig'' so that you can always copy it back if you make a mistake.</ul> | |||
<ul> There are many different text editors available for Linux but systems almost always include some version of '''vi''' or '''nano''' so those are the two we'll focus on.</ul> | |||
<li> In your ssh window open the ''index.html'' file in nano.</li> | |||
<ul>NOTE: Because your user does not own this file you may need to edit the file as the superuser.</ul> | |||
<code>nano index.html</code> | |||
<ul>[[File:nano_index_html.png|link=https://wiki.ihitc.net/mediawiki/images/d/d3/Nano_index_html.png|250px]]</ul> | |||
<ul>[[Media:nano_index_html.png|Click for Larger Image]]</ul> | |||
<li> Try navigating around the file with your arrow keys and changing the "Apache2 Debian Default Page" text at the top of the page to "Welcome to My Linux Webserver" | |||
<ul> Basic instructions for using nano abound on the Internet. You can get a basic introduction [http://staffwww.fullcoll.edu/sedwards/Nano/IntroToNano.html here] but it basically comes down to the menu lines at the bottom of the screen showing what your options are. The ^ character is commonly used to indicate the CTRL key so to exit the program (you will be prompted to save changes if you have made any) press CTRL-X or to save without exiting press CTRL-O and follow the prompts at the bottom of the screen.</ul> | |||
<li> Save your file with the changed text and then reload the page in your browser on your host system to see if the changes have taken effect.</li> | |||
<ul> Experiment with some of the nano menu options such as cutting and "un-cutting" lines of text and searching/replacing text. Once you are comfortable with the nano editor save your changes and exit.</ul> | |||
<ul> Make a note of which user and group owns your ''index.html'' file.</ul> | |||
<li> Delete your ''index.html'' file and copy your ''index.html.orig'' file back to ''index.html''</li> | |||
<ul> Try loading the website again and see if it's back to the original text. If you encounter an error it's possible that your ''index.html'' file is not readable by the webserver account so you should use the appropriate command to set the ''index.html'' file back to the owner and group of the original file.</ul> | |||
<li> Now open the ''index.html'' file in vi</li> | |||
<code> vi index.html</code> | |||
<ul>[[File:vi_index_html.png|link=https://wiki.ihitc.net/mediawiki/images/f/fd/Vi_index_html.png|250px]]</ul> | |||
<ul>[[Media:vi_index_html.png| Click for Larger Image]]</ul> | |||
<ul> The vi editor is probably considered more powerful than nano but is less user friendly without the menu at the bottom and a COMMAND mode as well as an INSERT mode. In the COMMAND mode you cannot directly change the text of the file by typing which can be frustrating to new users. Read through the vi tutorial [http://www.washington.edu/computing/unix/vi.html here] and try making some edits to your webpage. Once you are familiar with how the vi editor works save your file and exit.</ul> | |||
</ol> | |||
==Command Output Manipulation== | ==Command Output Manipulation== | ||
'''''[https://www.youtube.com/watch?v=dgC1r0rXTpA Video Tutorial - Command Output Manipulation]''''' | |||
<ol> | |||
<li> Change back to your home directory.</li> | |||
<code> cd ~</code> | |||
<li> Print out the files in your home directory.</li> | |||
<code> ls -al</code> | |||
<li> Now, run '''ls -al''' but redirect the output to a file using ''> filename''.</li> | |||
<code> ls -al > listfiles.txt</code> | |||
<ul> Notice how there is no command output. This is normal as you redirected the command output to the file ''listfiles.txt''</ul> | |||
<li> verify the contents of ''listfiles.txt''</li> | |||
<code> cat listfiles.txt</code> | |||
<ul>[[File:cat_listfiles_txt.png|link=https://wiki.ihitc.net/mediawiki/images/e/e1/Cat_listfiles_txt.png|250px]]</ul> | |||
<ul>[[Media:cat_listfiles_txt.png|Click for Larger Image]]</ul> | |||
<ul> Notice how it contains the exact same output as running '''ls -al''' on the command line.</ul> | |||
<li> Now, run:</li> | |||
<code>ls -al /var/log</code> | |||
<ul>Notice how many files there are in the ''/var/log'' directory. Lets say we wanted to just know the information of the ''debug'' log files. For this, we would use a pipe and the grep command.</ul> | |||
<li> So, now run:</li> | |||
<code> ls -al /var/log | grep debug</code> | |||
<ul>[[File:var_log_grep_debug.png|link=https://wiki.ihitc.net/mediawiki/images/7/74/Var_log_grep_debug.png|250px]]</ul> | |||
<ul>[[Media:var_log_grep_debug.png|Click for Larger Image]]</ul> | |||
<ul>Notice how the output is limited to all files that contain the string ''debug''.</ul> | |||
<ul> TIP: Grep is very powerful. Here we're just using it to search for a string but you can use it to search regular expressions as well. We mentioned these in a previous lab too. You can learn more about regular expressions at [https://regexone.com RegexOne] and [https://www.regular-expressions.info Regular-Expressions.info] among many other places. These are frequently used in system administration and programming so it's worth your while to get at least a basic understanding of them.</ul> | |||
<ul> Whats nice about pipes and redirects is that they can be used back to back on a command line creating a chain of programs which accept data as standard input and output it to the next program as standard output.</ul> | |||
<li> So lets say we have a scenario where we want to get a file that contains all of the information from all ''.gz'' files in ''/var/log''. To do this, we would run:</li> | |||
<code> ls -al /var/log | grep .gz > gzlogfiles.txt</code> | |||
<li> Now pipe the file into '''less'''</li> | |||
<code>cat gzlogfiles.txt | less</code> | |||
<ul> NOTE: Remember that you are now viewing the file in the less program and will need to quite the program to return to a command line. Type the letter "q" to quit the less program.</ul> | |||
<ul> In this case the piped '''cat''' command is the exact same as running '''less gzlogfiles.txt''' however there are many times where you need to connect two programs together with pipes in order to accomplish something which is otherwise not possible. Also, standard output can be non-text data as well. For example, it's possible to use pipes to pass audio data between programs such as one that scans a WAV file and adjusts the volume before piping it to an MP3 compression utility which saves the result as an MP3 file.</ul> | |||
<li> See if you can figure out how to view the output of '''ls -al /var/log | grep .gz''' one page at a time without dumping it to a text file first.</li> | |||
<li> Now remove the files ''gzlogfiles.txt'' and ''listfiles.txt'' that were created from this part of the lab.</li> | |||
</ol> | |||
==Searching for Files in Linux== | |||
'''''[https://www.youtube.com/watch?v=WSd6fq-jDyE Video Tutorial - Searching for Files in Linux]'''''<br> | |||
There are several ways to search for files on a Linux system. The simplest is to use the '''find''' command which searches through the system directory by directory for files which match your search string. You can specify many options for the find command which do things such as restrict to searching in one particular directory and it's sub-directories, etc. | |||
<ol> | |||
<li> Try searching your entire drive for files with syslog in the name. | |||
<code> find / -name syslog 2> /dev/null</code> | |||
<ul>[[File:find_syslog.png|link=https://wiki.ihitc.net/mediawiki/images/9/96/Find_syslog.png|250px]]</ul> | |||
<ul>[[Media:find_syslog.png|Click for Larger Image]]</ul> | |||
<ul> Notice the ''2> /dev/null'' on the end of the command. This redirects error messages ( ''2>'' redirected stderr, ''>'' redirects stdout as discussed above) to the location ''/dev/null'' which is non-existing location/file where bits are just dropped from the system. The reason we're redirecting the error messages is that there are a number of files or directories which you may not have permission to access. Each attempt to access these by the '''find''' program would create an error message (so lots of errors). We're basically telling the system to hide these error messages from us.</ul> | |||
<ul> You should see some files identified which contain the name ''syslog''. The problem is that the find command is very slow at moving through all the files on the system, in fact it may even appear to be frozen while searching slowly though the drive. If you have waited a while and are still not getting back to a command prompt you can press CTRL-C to force the find program to quit and return to a command prompt. This means the find program works just fine for searching through a few directories/files (such as your home directory might contain) but is not the best choice for searching the entire system. If you want to learn more about advanced uses of the find command take a look at [http://content.hccfl.edu/pollock/unix/findcmd.htm this tutorial].</ul> | |||
<li> A faster way to search the entire system is to use the ''locate'' command. Install the '''locate''' program</li> | |||
<ul>This command searches a pre-built database of all files on the system which means it operates much faster than searching though files one at a time. There are two downsides to locate. First, it may not be pre-installed on many Linux systems so you may have to install it. Second, you need to build or update the database before you can search for files. New files are not automatically updated to the database so this only really works if you periodically remember to update the database. We'll explain how you can schedule that automatically in the future (hint, see the '''cron''' program).</ul> | |||
<code> sudo apt-get install locate</code> | |||
<li> Create an updated database of files on your system</li> | |||
<code>sudo updatedb</code> | |||
<ul>Note, it will take a while for this program to find and index all the files on your system so give it a while to run. The advantage is after you do this you can search the database for many different files very quickly instead of waiting for each search as with the find command. We need to run the '''updatedb''' program as an administrator so that it can search though all locations on the system, including ones your user does not normally have access to.</ul> | |||
<ul> Note: Programs that may need to run for a long time and do not require user input (like '''updatedb''') can be run in the background by placing an ampersand at the end of the command line like '''sudo updatedb&'''. This will immediately return you to a command prompt so you can continue to work on other things while the command finishes running.</ul> | |||
<li> Search for files with ''syslog'' in the name again but now using the command ''locate''</li> | |||
<code> locate syslog</code> | |||
<ul>[[File:locate_syslog.png|link=https://wiki.ihitc.net/mediawiki/images/1/17/Locate_syslog.png|250px]]</ul> | |||
<ul>[[Media:locate_syslog.png|Click for Larger Image]]</ul> | |||
<ul> You should see many files found with this name and it should happen quickly, much faster than with the find command.</ul> | |||
</ol> | |||
==Creating Archived/Compressed Files== | ==Creating Archived/Compressed Files== | ||
'''''[https://www.youtube.com/watch?v=iBsHKvNP88E Video Tutorial - Creating Archived Compressed Files]'''''<br> | |||
If you get stuck or have any problems understanding why '''tar''' is functioning in a certain way you can find a number of introductory tutorials [http://www.thegeekstuff.com/2010/04/unix-tar-command-examples/ like this one] about using '''tar''' on the Internet by [https://www.google.com/#q=tar+tutorial searching for them] | |||
<ol> | |||
<li> Create a new directory ''experiments'' in your home directory.</li> | |||
<li> Create a GZipped TAR file of everything in your system log directory called ''logbackup1.tar.tz'' and save it to the ''experiments'' directory in your home directory by first changing your working directory to ''/var/log'' and then using the command:</li><br> | |||
<code>tar -czvf ~/experiments/logbackup1.tar.gz *</code> | |||
<ul> Note that you will need to use root privileges to create all of the log backups in this section of the lab because some log files can not be read by a standard user.</ul> | |||
<ul> Note the asterisk (*) which is used to select all files in the current directory for inclusion in the TAR file. This is a type of wildcard character.</ul> | |||
<li> Change your working directory to the ''experiments'' directory in your home directory.</li> | |||
<li> Try extracting the files into your ''experiments'' directory, show a list of files as they are extracted (''verbose'')</li> | |||
<ul> Check the contents of your ''experiments'' directory. What happened? What kind of mess could this make when you extract a TAR file when it was created this way?</ul> | |||
<li> Delete all files and subdirectories from inside the ''experiments'' directory.</li> | |||
<li> Try again to create a GZipped TAR file of everything in your system log directory called ''logbackup2.tar.tz'' and save it to the ''experiments'' directory in your home directory. By running the command from inside the ''experiments'' directory.</li> | |||
<code> tar -czvf logbackup2.tar.gz /var/log</code> | |||
<ul> Note that you will need to use root privileges to create all of the log backups in this section of the lab because some log files can not be read by a standard user.</ul> | |||
<ul> Note the lack of a slash at the end of the directory we are putting into the TAR file. In some older versions of TAR putting a slash on the end meant to put the files from that directory into the file but not the directory itself (just like when we created logbackup1.tar.gz with the asterisk wildcard). By leaving the slash off the end we are telling TAR to put the log directory,as well as it's contents, into the TAR file so that when we extract it we will get a log directory made with the files going into it. Even though new versions of TAR automatically prevent you from creating TAR files without a directory path it is still best practice to make sure that you are including a directory as part of the TAR file.</ul> | |||
<li> Try extracting the files into your ''experiments'' directory, show a list of files as they are extracted (''verbose'')</li> | |||
<li> Check the contents of your ''experiments'' directory.</li> | |||
<ul> What happened? If you extracted a tar file made this way you could potentially end up with several more levels of directories than you really want. In this case we got an extra var directory inside of experiments but if we were archiving something with a deeper path we would have even more extra subdirectories. You can actually see this during the tar file creation if you have verbose output enabled you saw that all the files being added to the tar had var/log/ in front of the filename. There are at least two ways to handle this which we will look at.</ul> | |||
<li> Delete all files and subdirectories from inside the ''experiments'' directory.</li> | |||
<ul> If we are creating the TAR file manually we can avoid these extra parts to the path by paying attention to what directory we are in when we create the TAR file.</ul> | |||
<li> This time change your working directory to ''/var'' first and then run the command.</li> | |||
<code> tar -czvf ~/experiments/logbackup3.tar.gz log</code> | |||
<ul> Note the different output from the tar command. This time the filenames are prefixed only by ''log/''.</ul> | |||
<li> Switch back to your ''experiments'' directory and then try extracting the files from ''logbackup3.tar.gz'' into your experiments directory, do not show a list of files as they are extracted this time.</li> | |||
<ul> Check the contents of your experiments directory. This time you should see that there is just one new subdirectory called log and all of the files are neatly placed inside of it. This is the type of extraction people normally want and expect from a tar file that is distributed.</ul> | |||
<li> Empty your ''experiments'' directory</li> | |||
<li> If you want to have the same effect without changing your working directory that is possible too. Try running the command below.</li> | |||
<code>tar -czvf ~/experiments/logbackup4.tar.gz -C /var log</code> | |||
<ul>This time it doesn't make any difference which directory on the system because we have again specified a full path for where to save the tar file and we have also told tar to change to the ''/var'' directory before adding the log directory to the file using the -C argument. This automates the process of manually changing directories like we did above.</ul> | |||
<li> Switch back to your ''experiments'' directory and then try extracting the files from ''logbackup4.tar.gz'' into your experiments directory, do not show a list of files as they are extracted this time.</li> | |||
<ul> Check the contents of your experiments directory. This time you should again see that there is just one new subdirectory called ''log'' and all of the files are neatly placed inside of it.</ul> | |||
<ul> There are a number of other things you can do with '''tar''' such as creating slower but more highly compressed .bz2 bzip files, extracting single files (or directories or groups of files) from an archive, listing the contents of an archive without extracting (which can show you if a new subdirectory will be created), adding files to an existing archive, and preserving file ownership (only by extracting on the same system though) and permissions. You should read the manual page for tar and then try practicing some of these and be familiar with the many ways that '''tar''' can be used.</ul> | |||
</ol> | |||
==Working With Filesystem Links== | ==Working With Filesystem Links== | ||
'''''[https://www.youtube.com/watch?v=vBorZKMmvIk Video Tutorial - Working With Filesystem Links]'''''<br> | |||
If you get stuck or have any problems understanding how links are functioning in a certain way you can find a number of introductory tutorials [http://www.nixtutor.com/freebsd/understanding-symbolic-links/ like this one] or [http://www.thegeekstuff.com/2010/10/linux-ln-command-examples/ more advanced tutorials] on the Internet by searching for them. | |||
<ol> | |||
<li> Use root privileges to create a new directory inside the ''var'' directory called ''system-documentation'' and change the ownership permissions so that your standard user has permission to read, write, and execute as a member of a group which owns the documentation directory. You will also need to make sure that all system users have execute permission for the parent directory (''/var'') in order to access anything in it including the ''system-documentation'' directory.</li> | |||
<ul> Instead of needing to go into the ''/var/-system-documentation'' directory all the time it would be more convenient if your user was able to reach that directory through a link in their own home directory.</ul> | |||
<li> Run the command below inside your regular user's home directory</li> | |||
<code>ln -s /var/system-documentation documentation</code> | |||
<ul>[[File:ln_documentation.png|link=https://wiki.ihitc.net/mediawiki/images/9/97/Ln_documentation.png|250px]]</ul> | |||
<ul>[[Media:ln_documentation.png|Click for Larger Image]]</ul> | |||
<ul>Or if you're in a different working directory you can run the command as '''ln -s /var/system-documentation ~/documentation''' Do you understand why?</ul> | |||
<ul> You should now see a soft link (also called symlink) in your home directory called documentation which points to the ''/var/system-documentation'' folder.</ul> | |||
<li> '''cd''' into the link just like it was a real directory.</li> | |||
<ul> If you use the '''pwd''' command to print your working directory while inside the link it will look like it's a directory. Almost all software on the system will interact with the link just as if it's a real directory.</ul> | |||
<li> Try creating some files and subdirectories inside of the link and then verify they are showing up in the real ''/var/system-documentation'' location as well. This should work correctly if your permissions are all set correctly.</li> | |||
<li> Remove the link</li> | |||
<code>rm ~/documentation</code> | |||
<ul> You should see that all of the files you created are still in ''/var/system-documentation''</ul> | |||
<ul> If you re-create the link you should be able to go back into ''~/documentation'' and remove files and directories and see they are removed from the actual ''/var/system-documentation'' directory as well</ul> | |||
<ul> You can also practice creating links to specific files as well as directories. Links do not override permissions so you need to have permission to read, write or execute the file or directory you are linking to just like if you actually changed to the real location of the item. Go ahead and practice creating and removing links until you have a good understanding of how links can be used.</ul> | |||
</ol> | |||
Note: If you are using '''tar''' to back up data, depending on exactly what you want to do you may want to use the ''-h'' or ''--dereference'' option which will follow the symlink and backup the data it contains. Normal behavior for tar would just be to back up the link itslef, not the file(s) pointed to by the link. You should try creating some tar files of directories which contain symlinks, deleting the data the symlink points to and the extracting the tar file to some new location to see this in action if you are not confident that you understand this. | |||
=Checking your Work= | |||
<ol> | |||
<li> You should have the following directories and files:</li> | |||
# ~/documentation | |||
# ~/experiments | |||
# /var/www/html/index.html | |||
<li> Use the following command to see if locate is installed:</li> | |||
<code> dpkg -s locate</code> | |||
<br><br> | |||
<li> Automatically check your results by running this command:</li> | |||
<code><nowiki> | |||
curl https://raw.githubusercontent.com/mnjk-inver/Linux-2480-Rebuild/main/lab_04_test.py | python3 | |||
</nowiki></code> | |||
</ol> | |||
<br><br> | |||
=Web App= | |||
You can check your progress on any of the labs in the ITC-2480 course from a webapp from this link: <br> | |||
[http://webcheck.itc2480.campus.ihitc.net webcheck.itc2480.campus.ihitc.net]<br> | |||
You must be logged into the campus VPN to use this application. | |||
Latest revision as of 02:50, 25 August 2021
Introduction
Linux is a very text file-oriented operating system. As we've learned most of the settings for the operating system are held in text files in the /etc directory and most of the commands that are used to manipulate the system take text input or give text output. Beause of this it's very important to be able to edit and manipulate text on the system which will be a key focus of this lab. In addition, we'll practice creating compressed files, which is useful for backing up files, and creating links between locations on the system.
In this lab you will perform the following tasks:
- Edit text files using nano and vi
- Learn how to manipulate command output
- Search for files
- Archive and Compress files using tar
- Create links between directories
You will be introduced to the following commands:
Lab Procedure
Prerequisites
Open an SSH console to your Linux system using the PuTTY software, login with your standard user account
Text File Editing
Video Tutorial - Text File Editing
- Change to the /var/www/html directory which is where the Apache webserver stores it's site files by default.
- Open up a web browser on your host computer and verify that you can browse to the IP address of your Linux system and still see the "It works" page that you saw in lab 2 after installing Apache.
- In your ssh window open the index.html file in nano.
- Try navigating around the file with your arrow keys and changing the "Apache2 Debian Default Page" text at the top of the page to "Welcome to My Linux Webserver"
- Basic instructions for using nano abound on the Internet. You can get a basic introduction here but it basically comes down to the menu lines at the bottom of the screen showing what your options are. The ^ character is commonly used to indicate the CTRL key so to exit the program (you will be prompted to save changes if you have made any) press CTRL-X or to save without exiting press CTRL-O and follow the prompts at the bottom of the screen.
- Save your file with the changed text and then reload the page in your browser on your host system to see if the changes have taken effect.
- Delete your index.html file and copy your index.html.orig file back to index.html
- Now open the index.html file in vi
- Verify you can see an index.html file inside of this directory by listing the contents of the directory. Note who the owner and group owner of the file are.
- Before we start making any changes it's a good idea to save an unmodified copy of the file you'll be working on so make a copy of the index.html file and name the copy index.html.orig so that you can always copy it back if you make a mistake.
- There are many different text editors available for Linux but systems almost always include some version of vi or nano so those are the two we'll focus on.
- NOTE: Because your user does not own this file you may need to edit the file as the superuser.
nano index.html
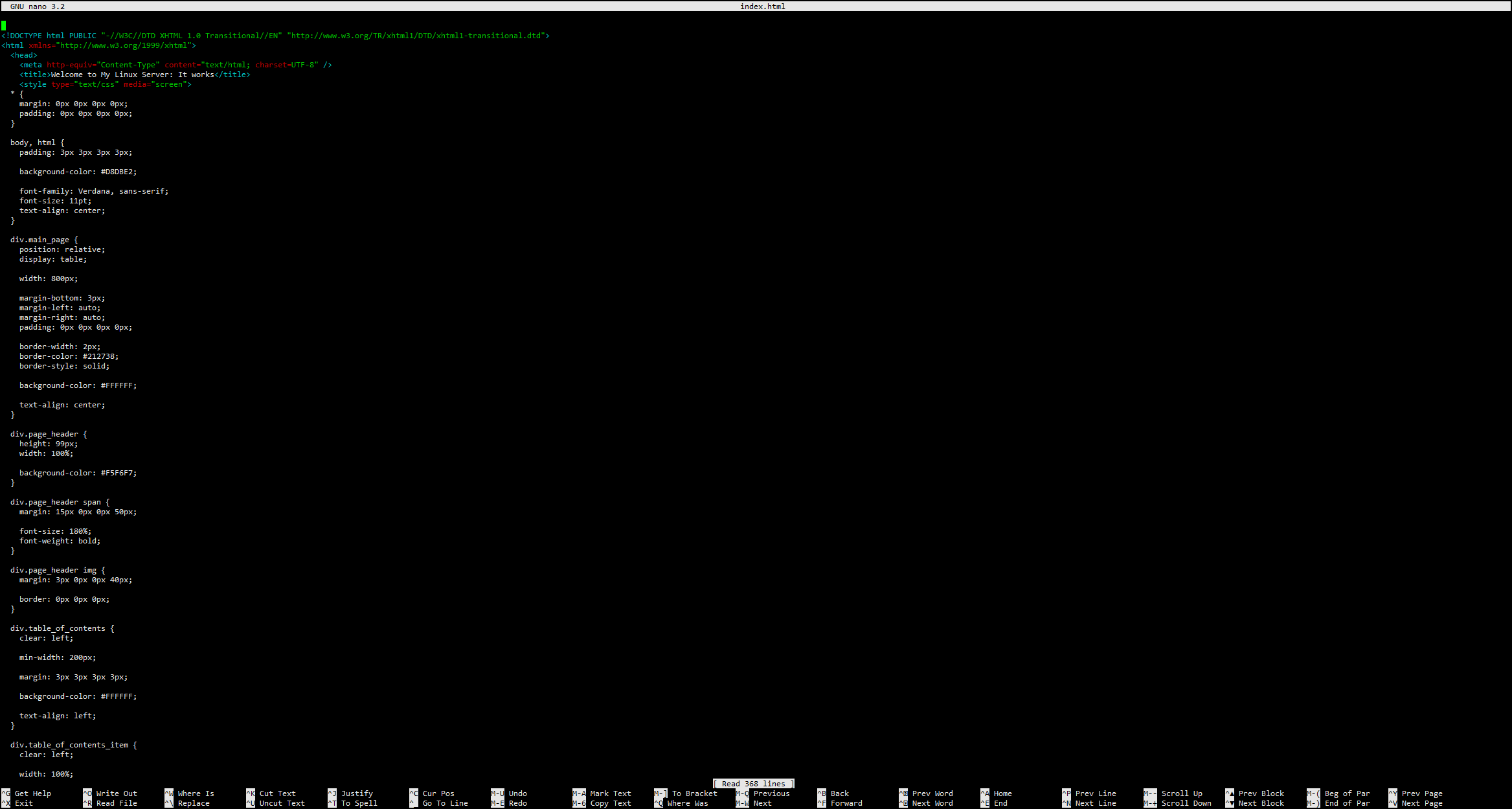
- Experiment with some of the nano menu options such as cutting and "un-cutting" lines of text and searching/replacing text. Once you are comfortable with the nano editor save your changes and exit.
- Make a note of which user and group owns your index.html file.
- Try loading the website again and see if it's back to the original text. If you encounter an error it's possible that your index.html file is not readable by the webserver account so you should use the appropriate command to set the index.html file back to the owner and group of the original file.
vi index.html

- The vi editor is probably considered more powerful than nano but is less user friendly without the menu at the bottom and a COMMAND mode as well as an INSERT mode. In the COMMAND mode you cannot directly change the text of the file by typing which can be frustrating to new users. Read through the vi tutorial here and try making some edits to your webpage. Once you are familiar with how the vi editor works save your file and exit.
Command Output Manipulation
Video Tutorial - Command Output Manipulation
- Change back to your home directory.
- Print out the files in your home directory.
- Now, run ls -al but redirect the output to a file using > filename.
- verify the contents of listfiles.txt
- Now, run:
- So, now run:
- So lets say we have a scenario where we want to get a file that contains all of the information from all .gz files in /var/log. To do this, we would run:
- Now pipe the file into less
- See if you can figure out how to view the output of ls -al /var/log | grep .gz one page at a time without dumping it to a text file first.
- Now remove the files gzlogfiles.txt and listfiles.txt that were created from this part of the lab.
cd ~
ls -al
ls -al > listfiles.txt
- Notice how there is no command output. This is normal as you redirected the command output to the file listfiles.txt
cat listfiles.txt
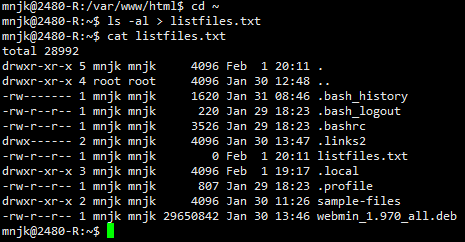
- Notice how it contains the exact same output as running ls -al on the command line.
ls -al /var/log
- Notice how many files there are in the /var/log directory. Lets say we wanted to just know the information of the debug log files. For this, we would use a pipe and the grep command.
ls -al /var/log | grep debug
- Notice how the output is limited to all files that contain the string debug.
- TIP: Grep is very powerful. Here we're just using it to search for a string but you can use it to search regular expressions as well. We mentioned these in a previous lab too. You can learn more about regular expressions at RegexOne and Regular-Expressions.info among many other places. These are frequently used in system administration and programming so it's worth your while to get at least a basic understanding of them.
- Whats nice about pipes and redirects is that they can be used back to back on a command line creating a chain of programs which accept data as standard input and output it to the next program as standard output.
ls -al /var/log | grep .gz > gzlogfiles.txt
cat gzlogfiles.txt | less
- NOTE: Remember that you are now viewing the file in the less program and will need to quite the program to return to a command line. Type the letter "q" to quit the less program.
- In this case the piped cat command is the exact same as running less gzlogfiles.txt however there are many times where you need to connect two programs together with pipes in order to accomplish something which is otherwise not possible. Also, standard output can be non-text data as well. For example, it's possible to use pipes to pass audio data between programs such as one that scans a WAV file and adjusts the volume before piping it to an MP3 compression utility which saves the result as an MP3 file.
Searching for Files in Linux
Video Tutorial - Searching for Files in Linux
There are several ways to search for files on a Linux system. The simplest is to use the find command which searches through the system directory by directory for files which match your search string. You can specify many options for the find command which do things such as restrict to searching in one particular directory and it's sub-directories, etc.
- Try searching your entire drive for files with syslog in the name.
find / -name syslog 2> /dev/null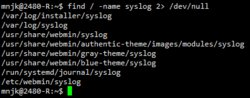
- Notice the 2> /dev/null on the end of the command. This redirects error messages ( 2> redirected stderr, > redirects stdout as discussed above) to the location /dev/null which is non-existing location/file where bits are just dropped from the system. The reason we're redirecting the error messages is that there are a number of files or directories which you may not have permission to access. Each attempt to access these by the find program would create an error message (so lots of errors). We're basically telling the system to hide these error messages from us.
- You should see some files identified which contain the name syslog. The problem is that the find command is very slow at moving through all the files on the system, in fact it may even appear to be frozen while searching slowly though the drive. If you have waited a while and are still not getting back to a command prompt you can press CTRL-C to force the find program to quit and return to a command prompt. This means the find program works just fine for searching through a few directories/files (such as your home directory might contain) but is not the best choice for searching the entire system. If you want to learn more about advanced uses of the find command take a look at this tutorial.
- A faster way to search the entire system is to use the locate command. Install the locate program
- Create an updated database of files on your system
- Search for files with syslog in the name again but now using the command locate
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- This command searches a pre-built database of all files on the system which means it operates much faster than searching though files one at a time. There are two downsides to locate. First, it may not be pre-installed on many Linux systems so you may have to install it. Second, you need to build or update the database before you can search for files. New files are not automatically updated to the database so this only really works if you periodically remember to update the database. We'll explain how you can schedule that automatically in the future (hint, see the cron program).
sudo apt-get install locate
sudo updatedb
- Note, it will take a while for this program to find and index all the files on your system so give it a while to run. The advantage is after you do this you can search the database for many different files very quickly instead of waiting for each search as with the find command. We need to run the updatedb program as an administrator so that it can search though all locations on the system, including ones your user does not normally have access to.
- Note: Programs that may need to run for a long time and do not require user input (like updatedb) can be run in the background by placing an ampersand at the end of the command line like sudo updatedb&. This will immediately return you to a command prompt so you can continue to work on other things while the command finishes running.
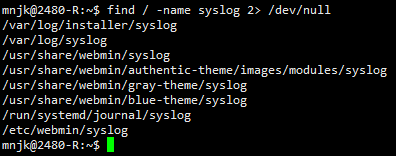
locate syslog
{kind=link}
- You should see many files found with this name and it should happen quickly, much faster than with the find command.
Creating Archived/Compressed Files
Video Tutorial - Creating Archived Compressed Files
If you get stuck or have any problems understanding why tar is functioning in a certain way you can find a number of introductory tutorials like this one about using tar on the Internet by searching for them
- Create a new directory experiments in your home directory.
- Create a GZipped TAR file of everything in your system log directory called logbackup1.tar.tz and save it to the experiments directory in your home directory by first changing your working directory to /var/log and then using the command:
- Change your working directory to the experiments directory in your home directory.
- Try extracting the files into your experiments directory, show a list of files as they are extracted (verbose)
- Delete all files and subdirectories from inside the experiments directory.
- Try again to create a GZipped TAR file of everything in your system log directory called logbackup2.tar.tz and save it to the experiments directory in your home directory. By running the command from inside the experiments directory.
- Try extracting the files into your experiments directory, show a list of files as they are extracted (verbose)
- Check the contents of your experiments directory.
- Delete all files and subdirectories from inside the experiments directory.
- This time change your working directory to /var first and then run the command.
- Switch back to your experiments directory and then try extracting the files from logbackup3.tar.gz into your experiments directory, do not show a list of files as they are extracted this time.
- Empty your experiments directory
- If you want to have the same effect without changing your working directory that is possible too. Try running the command below.
- Switch back to your experiments directory and then try extracting the files from logbackup4.tar.gz into your experiments directory, do not show a list of files as they are extracted this time.
tar -czvf ~/experiments/logbackup1.tar.gz *
- Note that you will need to use root privileges to create all of the log backups in this section of the lab because some log files can not be read by a standard user.
- Note the asterisk (*) which is used to select all files in the current directory for inclusion in the TAR file. This is a type of wildcard character.
- Check the contents of your experiments directory. What happened? What kind of mess could this make when you extract a TAR file when it was created this way?
tar -czvf logbackup2.tar.gz /var/log
- Note that you will need to use root privileges to create all of the log backups in this section of the lab because some log files can not be read by a standard user.
- Note the lack of a slash at the end of the directory we are putting into the TAR file. In some older versions of TAR putting a slash on the end meant to put the files from that directory into the file but not the directory itself (just like when we created logbackup1.tar.gz with the asterisk wildcard). By leaving the slash off the end we are telling TAR to put the log directory,as well as it's contents, into the TAR file so that when we extract it we will get a log directory made with the files going into it. Even though new versions of TAR automatically prevent you from creating TAR files without a directory path it is still best practice to make sure that you are including a directory as part of the TAR file.
- What happened? If you extracted a tar file made this way you could potentially end up with several more levels of directories than you really want. In this case we got an extra var directory inside of experiments but if we were archiving something with a deeper path we would have even more extra subdirectories. You can actually see this during the tar file creation if you have verbose output enabled you saw that all the files being added to the tar had var/log/ in front of the filename. There are at least two ways to handle this which we will look at.
- If we are creating the TAR file manually we can avoid these extra parts to the path by paying attention to what directory we are in when we create the TAR file.
tar -czvf ~/experiments/logbackup3.tar.gz log
- Note the different output from the tar command. This time the filenames are prefixed only by log/.
- Check the contents of your experiments directory. This time you should see that there is just one new subdirectory called log and all of the files are neatly placed inside of it. This is the type of extraction people normally want and expect from a tar file that is distributed.
tar -czvf ~/experiments/logbackup4.tar.gz -C /var log
- This time it doesn't make any difference which directory on the system because we have again specified a full path for where to save the tar file and we have also told tar to change to the /var directory before adding the log directory to the file using the -C argument. This automates the process of manually changing directories like we did above.
- Check the contents of your experiments directory. This time you should again see that there is just one new subdirectory called log and all of the files are neatly placed inside of it.
- There are a number of other things you can do with tar such as creating slower but more highly compressed .bz2 bzip files, extracting single files (or directories or groups of files) from an archive, listing the contents of an archive without extracting (which can show you if a new subdirectory will be created), adding files to an existing archive, and preserving file ownership (only by extracting on the same system though) and permissions. You should read the manual page for tar and then try practicing some of these and be familiar with the many ways that tar can be used.
Working With Filesystem Links
Video Tutorial - Working With Filesystem Links
If you get stuck or have any problems understanding how links are functioning in a certain way you can find a number of introductory tutorials like this one or more advanced tutorials on the Internet by searching for them.
- Use root privileges to create a new directory inside the var directory called system-documentation and change the ownership permissions so that your standard user has permission to read, write, and execute as a member of a group which owns the documentation directory. You will also need to make sure that all system users have execute permission for the parent directory (/var) in order to access anything in it including the system-documentation directory.
- Run the command below inside your regular user's home directory
- cd into the link just like it was a real directory.
- Try creating some files and subdirectories inside of the link and then verify they are showing up in the real /var/system-documentation location as well. This should work correctly if your permissions are all set correctly.
- Remove the link
- Instead of needing to go into the /var/-system-documentation directory all the time it would be more convenient if your user was able to reach that directory through a link in their own home directory.
ln -s /var/system-documentation documentation

{kind=link}
- Or if you're in a different working directory you can run the command as ln -s /var/system-documentation ~/documentation Do you understand why?
- You should now see a soft link (also called symlink) in your home directory called documentation which points to the /var/system-documentation folder.
- If you use the pwd command to print your working directory while inside the link it will look like it's a directory. Almost all software on the system will interact with the link just as if it's a real directory.
rm ~/documentation
- You should see that all of the files you created are still in /var/system-documentation
- If you re-create the link you should be able to go back into ~/documentation and remove files and directories and see they are removed from the actual /var/system-documentation directory as well
- You can also practice creating links to specific files as well as directories. Links do not override permissions so you need to have permission to read, write or execute the file or directory you are linking to just like if you actually changed to the real location of the item. Go ahead and practice creating and removing links until you have a good understanding of how links can be used.
Note: If you are using tar to back up data, depending on exactly what you want to do you may want to use the -h or --dereference option which will follow the symlink and backup the data it contains. Normal behavior for tar would just be to back up the link itslef, not the file(s) pointed to by the link. You should try creating some tar files of directories which contain symlinks, deleting the data the symlink points to and the extracting the tar file to some new location to see this in action if you are not confident that you understand this.
Checking your Work
- You should have the following directories and files:
- ~/documentation
- ~/experiments
- /var/www/html/index.html
- Use the following command to see if locate is installed:
- Automatically check your results by running this command:
dpkg -s locate
curl https://raw.githubusercontent.com/mnjk-inver/Linux-2480-Rebuild/main/lab_04_test.py | python3
Web App
You can check your progress on any of the labs in the ITC-2480 course from a webapp from this link:
webcheck.itc2480.campus.ihitc.net
You must be logged into the campus VPN to use this application.